Apache Flink 零基础入门(7):状态管理及容错机制¶
1 状态管理的基本概念¶
1.1 什么是状态¶

首先举一个无状态计算的例子:消费延迟计算。假设现在有一个消息队列,消息队列中有一个生产者持续往消费队列写入消息,多个消费者分别从消息队列中读取消息。从图上可以看出,生产者已经写入 16 条消息, Offset 停留在 15 ;有 3 个消费者,有的消费快,而有的消费慢。消费快的已经消费了 13 条数据,消费者慢的才消费了 7 、 8 条数据。
如何实时统计每个消费者落后多少条数据,如图给出了输入输出的示例。可以了解到输入的时间点有一个时间戳,生产者将消息写到了某个时间点的位置,每个消费者同一时间点分别读到了什么位置。刚才也提到了生产者写入了 15 条,消费者分别读取了 10 、 7 、 12 条。那么问题来了,怎么将生产者、消费者的进度转换为右侧示意图信息呢?
consumer 0 落后了 5 条, consumer 1 落后了 8 条, consumer 2 落后了 3 条,根据 Flink 的原理,此处需进行 Map 操作。 Map 首先把消息读取进来,然后分别相减,即可知道每个 consumer 分别落后了几条。 Map 一直往下发,则会得出最终结果。
大家会发现,在这种模式的计算中,无论这条输入进来多少次,输出的结果都是一样的,因为单条输入中已经包含了所需的所有信息。消费落后等于生产者减去消费者。生产者的消费在单条数据中可以得到,消费者的数据也可以在单条数据中得到,所以相同输入可以得到相同输出,这就是一个无状态的计算。
相应的什么是有状态的计算?
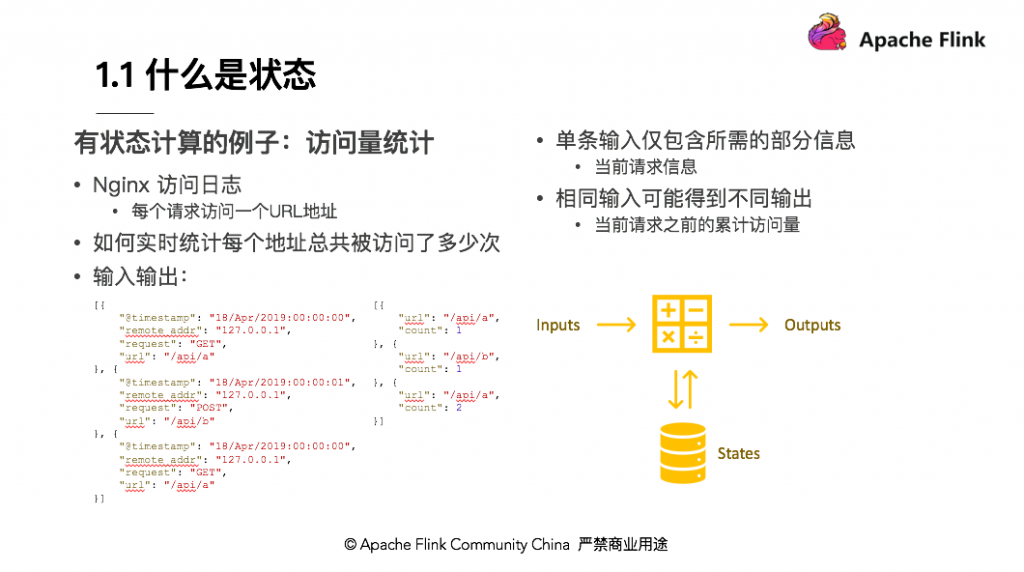
以访问日志统计量的例子进行说明,比如当前拿到一个 Nginx 访问日志,一条日志表示一个请求,记录该请求从哪里来,访问的哪个地址,需要实时统计每个地址总共被访问了多少次,也即每个 API 被调用了多少次。可以看到下面简化的输入和输出,输入第一条是在某个时间点请求 GET 了 /api/a ;第二条日志记录了某个时间点 Post /api/b ;第三条是在某个时间点 GET 了一个 /api/a ,总共有 3 个 Nginx 日志。从这 3 条 Nginx 日志可以看出,第一条进来输出 /api/a 被访问了一次,第二条进来输出 /api/b 被访问了一次,紧接着又进来一条访问 api/a ,所以 api/a 被访问了 2 次。不同的是,两条 /api/a 的 Nginx 日志进来的数据是一样的,但输出的时候结果可能不同,第一次输出 count=1 ,第二次输出 count=2 ,说明相同输入可能得到不同输出。输出的结果取决于当前请求的 API 地址之前累计被访问过多少次。第一条过来累计是 0 次, count = 1 ,第二条过来 API 的访问已经有一次了,所以 /api/a 访问累计次数 count=2 。单条数据其实仅包含当前这次访问的信息,而不包含所有的信息。要得到这个结果,还需要依赖 API 累计访问的量,即状态。
这个计算模式是将数据输入算子中,用来进行各种复杂的计算并输出数据。这个过程中算子会去访问之前存储在里面的状态。另外一方面,它还会把现在的数据对状态的影响实时更新,如果输入 200 条数据,最后输出就是 200 条结果。

什么场景会用到状态呢?下面列举了常见的 4 种:
-
去重:比如上游的系统数据可能会有重复,落到下游系统时希望把重复的数据都去掉。去重需要先了解哪些数据来过,哪些数据还没有来,也就是把所有的主键都记录下来,当一条数据到来后,能够看到在主键当中是否存在。
-
窗口计算:比如统计每分钟
Nginx日志API被访问了多少次。窗口是一分钟计算一次,在窗口触发前,如08:00 ~ 08:01这个窗口,前59秒的数据来了需要先放入内存,即需要把这个窗口之内的数据先保留下来,等到8:01时一分钟后,再将整个窗口内触发的数据输出。未触发的窗口数据也是一种状态。 -
机器学习或深度学习:如训练的模型以及当前模型的参数也是一种状态,机器学习可能每次都用有一个数据集,需要在数据集上进行学习,对模型进行一个反馈。
-
访问历史数据:比如与昨天的数据进行对比,需要访问一些历史数据。如果每次从外部去读,对资源的消耗可能比较大,所以也希望把这些历史数据也放入状态中做对比。
1.2 为什么要管理状态¶

管理状态最直接的方式就是将数据都放到内存中,这也是很常见的做法。比如在做 WordCount 时, Word 作为输入, Count 作为输出。在计算的过程中把输入不断累加到 Count 。
但对于流式作业有以下要求:
-
7*24小时运行,高可靠; -
数据不丢不重,恰好计算一次;
-
数据实时产出,不延迟;
基于以上要求,内存的管理就会出现一些问题。由于内存的容量是有限制的。如果要做 24 小时的窗口计算,将 24 小时的数据都放到内存,可能会出现内存不足;另外,作业是 7*24 ,需要保障高可用,机器若出现故障或者宕机,需要考虑如何备份及从备份中去恢复,保证运行的作业不受影响;此外,考虑横向扩展,假如网站的访问量不高,统计每个 API 访问次数的程序可以用单线程去运行,但如果网站访问量突然增加,单节点无法处理全部访问数据,此时需要增加几个节点进行横向扩展,这时数据的状态如何平均分配到新增加的节点也问题之一。因此,将数据都放到内存中,并不是最合适的一种状态管理方式。
1.3 理想的状态管理¶
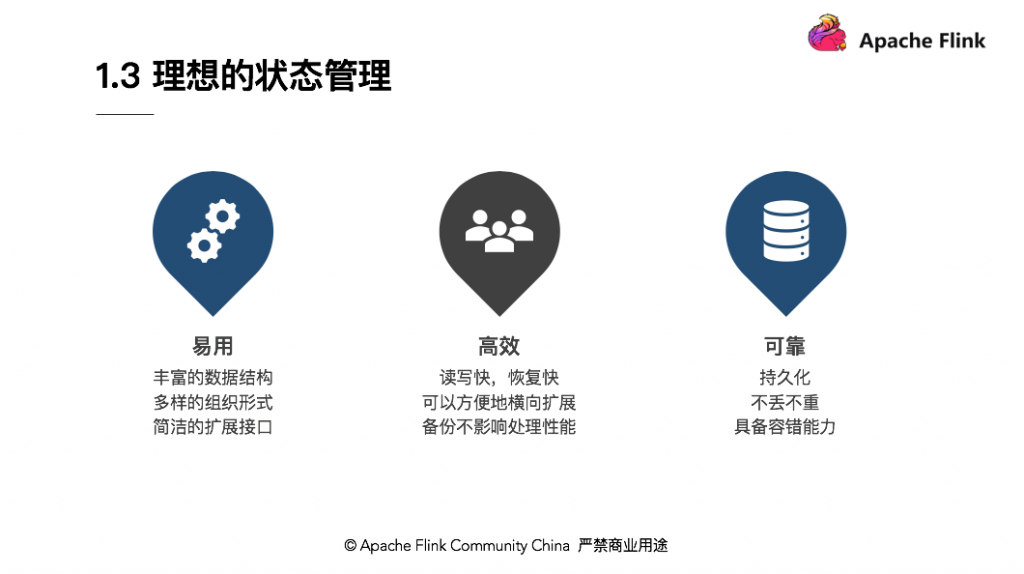
最理想的状态管理需要满足易用、高效、可靠三点需求:
-
易用,
Flink提供了丰富的数据结构、多样的状态组织形式以及简洁的扩展接口,让状态管理更加易用; -
高效,实时作业一般需要更低的延迟,一旦出现故障,恢复速度也需要更快;当处理能力不够时,可以横向扩展,同时在处理备份时,不影响作业本身处理性能;
-
可靠,
Flink提供了状态持久化,包括不丢不重的语义以及具备自动的容错能力,比如HA,当节点挂掉后会自动拉起,不需要人工介入。
2 Flink 状态的类型与使用示例¶
2.1 Managed State & Raw State¶

Managed State 是 Flink 自动管理的 State ,而 Raw State 是原生态 State ,两者的区别如下:
-
从状态管理方式的方式来说,
Managed State由Flink Runtime管理,自动存储,自动恢复,在内存管理上有优化;而Raw State需要用户自己管理,需要自己序列化,Flink不知道State中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构。 -
从状态数据结构来说,
Managed State支持已知的数据结构,如Value、List、Map等。而Raw State只支持字节数组,所有状态都要转换为二进制字节数组才可以。 -
从推荐使用场景来说,
Managed State大多数情况下均可使用,而Raw State是当Managed State不够用时,比如需要自定义Operator时,推荐使用Raw State。
2.2 Keyed State & Operator State¶

Managed State 分为两种,一种是 Keyed State ;另外一种是 Operator State 。在 Flink Stream 模型中, Datastream 经过 keyBy 的操作可以变为 KeyedStream 。
每个 Key 对应一个 State ,即一个 Operator 实例处理多个 Key ,访问相应的多个 State ,并由此就衍生了 Keyed State 。 Keyed State 只能用在 KeyedStream 的算子中,即在整个程序中没有 keyBy 的过程就没有办法使用 KeyedStream 。
相比较而言, Operator State 可以用于所有算子,相对于数据源有一个更好的匹配方式,常用于 Source ,例如 FlinkKafkaConsumer 。相比 Keyed State ,一个 Operator 实例对应一个 State ,随着并发的改变, Keyed State 中, State 随着 Key 在实例间迁移,比如原来有 1 个并发,对应的 API 请求过来, /api/a 和 /api/b 都存放在这个实例当中;如果请求量变大,需要扩容,就会把 /api/a 的状态和 /api/b 的状态分别放在不同的节点。由于 Operator State 没有 Key ,并发改变时需要选择状态如何重新分配。其中内置了 2 种分配方式:一种是均匀分配,另外一种是将所有 State 合并为全量 State 再分发给每个实例。
在访问上, Keyed State 通过 RuntimeContext 访问,这需要 Operator 是一个 Rich Function 。 Operator State 需要自己实现 CheckpointedFunction 或 ListCheckpointed 接口。在数据结构上, Keyed State 支持的数据结构,比如 ValueState 、 ListState 、 ReducingState 、 AggregatingState 和 MapState ;而 Operator State 支持的数据结构相对较少,如 ListState 。
2.3 Keyed State 使用示例¶
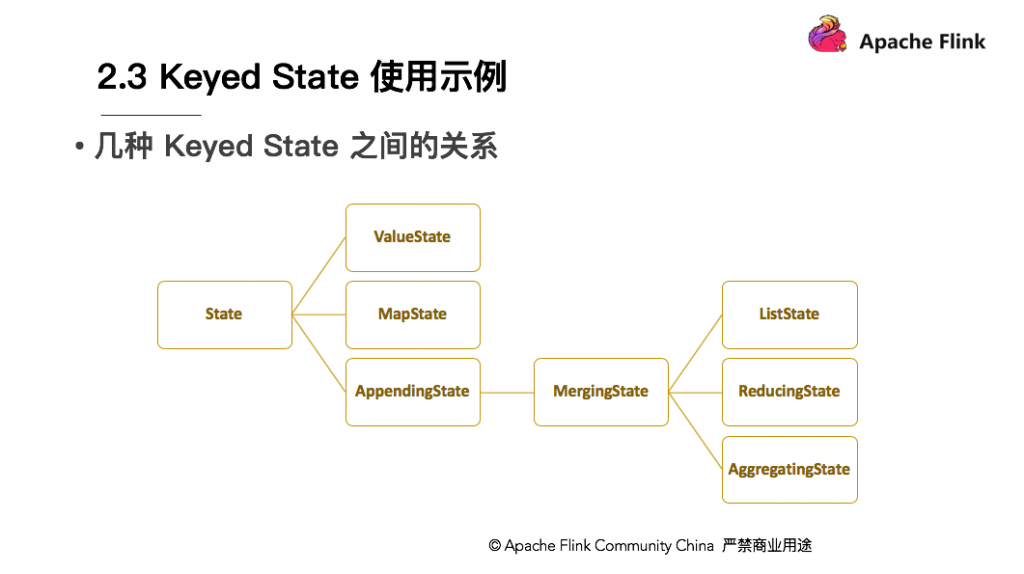
Keyed State 有很多种,如图为几种 Keyed State 之间的关系。首先 State 的子类中一级子类有 ValueState 、 MapState 、 AppendingState 。 AppendingState 又有一个子类 MergingState 。 MergingState 又分为 3 个子类分别是 ListState 、 ReducingState 、 AggregatingState 。这个继承关系使它们的访问方式、数据结构也存在差异。

几种 Keyed State 的差异具体体现在:
-
ValueState存储单个值,比如Wordcount,用Word当Key,State就是它的Count。这里面的单个值可能是数值或者字符串,作为单个值,访问接口可能有两种,get和set。在State上体现的是update(T) / T value()。 -
MapState的状态数据类型是Map,在State上有put、remove等。需要注意的是在MapState中的key和Keyed state中的key不是同一个。 -
ListState状态数据类型是List,访问接口如add、update等。 -
ReducingState和AggregatingState与ListState都是同一个父类,但状态数据类型上是单个值,原因在于其中的add方法不是把当前的元素追加到列表中,而是把当前元素直接更新进了Reducing的结果中。 -
AggregatingState的区别是在访问接口,ReducingState中add(T)和T get()进去和出来的元素都是同一个类型,但在AggregatingState输入的IN,输出的是OUT。

下面以 ValueState 为例,来阐述一下具体如何使用,以状态机的案例来讲解。
感兴趣的同学可直接查看完整源代码,在此截取部分。如图为 Flink 作业的主方法与主函数中的内容,前面的输入、后面的输出以及一些个性化的配置项都已去掉,仅保留了主干。
首先 events 是一个 DataStream ,通过 env.addSource 加载数据进来,接下来有一个 DataStream 叫 alerts ,先 keyby 一个 sourceAddress ,然后在 flatMap 一个StateMachineMapper 。 StateMachineMapper 就是一个状态机,状态机指有不同的状态与状态间有不同的转换关系的结合,以买东西的过程简单举例。首先下订单,订单生成后状态为待付款,当再来一个事件状态付款成功,则事件的状态将会从待付款变为已付款,待发货。已付款,待发货的状态再来一个事件发货,订单状态将会变为配送中,配送中的状态再来一个事件签收,则该订单的状态就变为已签收。在整个过程中,随时都可以来一个事件,取消订单,无论哪个状态,一旦触发了取消订单事件最终就会将状态转移到已取消,至此状态就结束了。
Flink 写状态机是如何实现的?首先这是一个 RichFlatMapFunction ,要用 Keyed State getRuntimeContext , getRuntimeContext 的过程中需要 RichFunction ,所以需要在 open 方法中获取 currentState ,然后 getState , currentState 保存的是当前状态机上的状态。
如果刚下订单,那么 currentState 就是待付款状态,初始化后, currentState 就代表订单完成。订单来了后,就会走 flatMap 这个方法,在 flatMap 方法中,首先定义一个 State ,从 currentState 取出,即 Value , Value 取值后先判断值是否为空,如果 sourceAddress state 是空,则说明没有被使用过,那么此状态应该为刚创建订单的初始状态,即待付款。然后赋值 state = State.Initial ,注意此处的 State 是本地的变量,而不是 Flink 中管理的状态,将它的值从状态中取出。接下来在本地又会来一个变量,然后 transition ,将事件对它的影响加上,刚才待付款的订单收到付款成功的事件,就会变成已付款,待发货,然后 nextState 即可算出。此外,还需要判断 State 是否合法,比如一个已签收的订单,又来一个状态叫取消订单,会发现已签收订单不能被取消,此时这个状态就会下发,订单状态为非法状态。
如果不是非法的状态,还要看该状态是否已经无法转换,比如这个状态变为已取消时,就不会在有其他的状态再发生了,此时就会从 state 中 clear 。 clear 是所有的 Flink 管理 keyed state 都有的公共方法,意味着将信息删除,如果既不是一个非法状态也不是一个结束状态,后面可能还会有更多的转换,此时需要将订单的当前状态 update ,这样就完成了 ValueState 的初始化、取值、更新以及清零,在整个过程中状态机的作用就是将非法的状态进行下发,方便下游进行处理。其他的状态也是类似的使用方式。
3 容错机制与故障恢复¶
3.1 状态如何保存及恢复¶

Flink 状态保存主要依靠 Checkpoint 机制, Checkpoint 会定时制作分布式快照,对程序中的状态进行备份。分布式快照是如何实现的可以参考【第二课时】的内容,这里就不再阐述分布式快照具体是如何实现的。分布式快照 Checkpoint 完成后,当作业发生故障了如何去恢复?假如作业分布跑在 3 台机器上,其中一台挂了。这个时候需要把进程或者线程移到 active 的 2 台机器上,此时还需要将整个作业的所有 Task 都回滚到最后一次成功 Checkpoint 中的状态,然后从该点开始继续处理。
如果要从 Checkpoint 恢复,必要条件是数据源需要支持数据重新发送。 Checkpoint 恢复后, Flink 提供两种一致性语义,一种是恰好一次,一种是至少一次。在做 Checkpoint 时,可根据 Barries 对齐来判断是恰好一次还是至少一次,如果对齐,则为恰好一次,否则没有对齐即为至少一次。如果只有一个上游,也就是说 Barries 是不需要对齐的的;如果只有一个 Checkpoint 在做,不管什么时候从 Checkpoint 恢复,都会恢复到刚才的状态;如果有多个上游,假如一个上游的 Barries 到了,另一个 Barries 还没有来,如果这个时候对状态进行快照,那么从这个快照恢复的时候其中一个上游的数据可能会有重复。
Checkpoint 通过代码的实现方法如下:
-
首先从作业的运行环境
env.enableCheckpointing传入1000,意思是做2个Checkpoint的事件间隔为1秒。Checkpoint做的越频繁,恢复时追数据就会相对减少,同时Checkpoint相应的也会有一些IO消耗。 -
接下来是设置
Checkpoint的model,即设置了Exactly_Once语义,表示需要Barrier对齐,这样可以保证消息不会丢失也不会重复。 -
setMinPauseBetweenCheckpoints是2个Checkpoint之间最少是要等500ms,也就是刚做完一个Checkpoint。比如某个Checkpoint做了700ms,按照原则过300ms应该是做下一个Checkpoint,因为设置了1000ms做一次Checkpoint的,但是中间的等待时间比较短,不足500ms了,需要多等200ms,因此以这样的方式防止Checkpoint太过于频繁而导致业务处理的速度下降。 -
setCheckpointTimeout表示做Checkpoint多久超时,如果Checkpoint在1min之内尚未完成,说明Checkpoint超时失败。 -
setMaxConcurrentCheckpoints表示同时有多少个Checkpoint在做快照,这个可以根据具体需求去做设置。 -
enableExternalizedCheckpoints表示下Cancel时是否需要保留当前的Checkpoint,默认Checkpoint会在整个作业Cancel时被删除。Checkpoint是作业级别的保存点。
上面讲过,除了故障恢复之外,还需要可以手动去调整并发重新分配这些状态。手动调整并发,必须要重启作业并会提示 Checkpoint 已经不存在,那么作业如何恢复数据?
一方面 Flink 在 Cancel 时允许在外部介质保留 Checkpoint ;另一方面, Flink 还有另外一个机制是 SavePoint 。

Savepoint 与 Checkpoint 类似,同样是把状态存储到外部介质。当作业失败时,可以从外部恢复。 Savepoint 与 Checkpoint 有什么区别呢?
-
从触发管理方式来讲,
Checkpoint由Flink自动触发并管理,而Savepoint由用户手动触发并人肉管理; -
从用途来讲,
Checkpoint在Task发生异常时快速恢复,例如网络抖动或超时异常,而Savepoint有计划地进行备份,使作业能停止后再恢复,例如修改代码、调整并发; -
最后从特点来讲,
Checkpoint比较轻量级,作业出现问题会自动从故障中恢复,在作业停止后默认清除;而Savepoint比较持久,以标准格式存储,允许代码或配置发生改变,恢复需要启动作业手动指定一个路径恢复。
3.2 可选的状态存储方式¶

Checkpoint 的存储,第一种是内存存储,即 MemoryStateBackend ,构造方法是设置最大的 StateSize ,选择是否做异步快照,这种存储状态本身存储在 TaskManager 节点也就是执行节点内存中的,因为内存有容量限制,所以单个 State maxStateSize 默认 5 M ,且需要注意 maxStateSize <= akka.framesize 默认 10 M 。 Checkpoint 存储在 JobManager 内存中,因此总大小不超过 JobManager 的内存。推荐使用的场景为:本地测试、几乎无状态的作业,比如 ETL 、 JobManager 不容易挂,或挂掉影响不大的情况。不推荐在生产场景使用。

另一种就是在文件系统上的 FsStateBackend ,构建方法是需要传一个文件路径和是否异步快照。 State 依然在 TaskManager 内存中,但不会像 MemoryStateBackend 有 5 M 的设置上限, Checkpoint 存储在外部文件系统(本地或 HDFS ),打破了总大小 Jobmanager 内存的限制。容量限制上,单 TaskManager 上 State 总量不超过它的内存,总大小不超过配置的文件系统容量。推荐使用的场景、常规使用状态的作业、例如分钟级窗口聚合或 join 、需要开启 HA 的作业。

还有一种存储为 RocksDBStateBackend , RocksDB 是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,但需要注意 RocksDB 不支持同步的 Checkpoint ,构造方法中没有同步快照这个选项。不过 RocksDB 支持增量的 Checkpoint ,也是目前唯一增量 Checkpoint 的 Backend ,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或 HDFS ),其容量限制只要单个 TaskManager 上 State 总量不超过它的 内存+磁盘 ,单 Key 最大 2G ,总大小不超过配置的文件系统容量即可。推荐使用的场景为:超大状态的作业,例如天级窗口聚合、需要开启 HA 的作业、最好是对状态读写性能要求不高的作业。
4 总结¶
4.1 为什么要使用状态?¶
前面提到有状态的作业要有有状态的逻辑,有状态的逻辑是因为数据之间存在关联,单条数据是没有办法把所有的信息给表现出来。所以需要通过状态来满足业务逻辑。
4.2 为什么要管理状态?¶
使用了状态,为什么要管理状态?因为实时作业需要 7*24 不间断的运行,需要应对不可靠的因素而带来的影响。
4.3 如何选择状态的类型和存储方式?¶
那如何选择状态的类型和存储方式?结合前面的内容,可以看到,首先是要分析清楚业务场景;比如想要做什么,状态到底大不大。比较各个方案的利弊,选择根据需求合适的状态类型和存储方式即可。