6.8.6 Runtime Filter¶
Runtime Filter 主要分为两种, Join Runtime Filter 与 TopN Runtime Filter 。本文将详细介绍两类 Runtime Filter 的工作原理、使用指南与调优方法。
1 Join Runtime Filter¶
Join Runtime Filter (以下简称 JRF )是一种优化技术,它根据运行时数据在 Join 节点通过 Join 条件动态生成 Filter 。此技术不仅能降低 Join Probe 的规模,还能有效减少数据 IO 和网络传输。
1.1 工作原理¶
我们以一个类似 TPC-H Schema 上的 Join 为例,来说明 JRF 的工作原理。
假设数据库中有两张表:
-
订单表(
orders),包含1亿行数据,记录订单号(o_orderkey)、客户编号(o_custkey)以及订单的其它信息。 -
客户表(
customer),包含10万行数据,记录客户编号(c_custkey)、客户国籍(c_nation)以及客户的其它信息。该表共记录了25个国家的客户,每个国家约有4千客户。
统计客户来自中国的订单数量,查询语句如下:
| SQL | |
|---|---|
1 2 3 | |
此查询的执行计划主体是一个 Join ,如下图所示:

在没有 JRF 的情况下, Scan 节点会扫描 orders 表,读入 1 亿行数据, Join 节点则对这 1 亿行数据进行 Hash Probe ,最后生成 Join 结果。
-
优化思路
过滤条件
c_nation = "china"会过滤掉所有非中国的客户,因此参与Join的customer只是customer表的一部分(约1/25)。后续的Join条件为o_custkey = c_custkey,所以我们需要关注过滤结果中c_custkey列有哪些被选中的custkey。将过滤后的c_custkey记为集合A。在下文中,我们用集合A专门指代参与Join的c_custkey集合。如果将集合
A作为一个in条件推给orders表,那么orders表的Scan节点就可以对orders进行过滤。这就类似增加了一个过滤条件c_custkey in (c001, c003)。基于以上的优化思路,
SQL可以优化为:SQL 1 2 3
select count(*) from orders join customer on o_custkey = c_custkey where c_nation = "china" and o_custkey in (c001, c003)优化后的执行计划如下图所示:
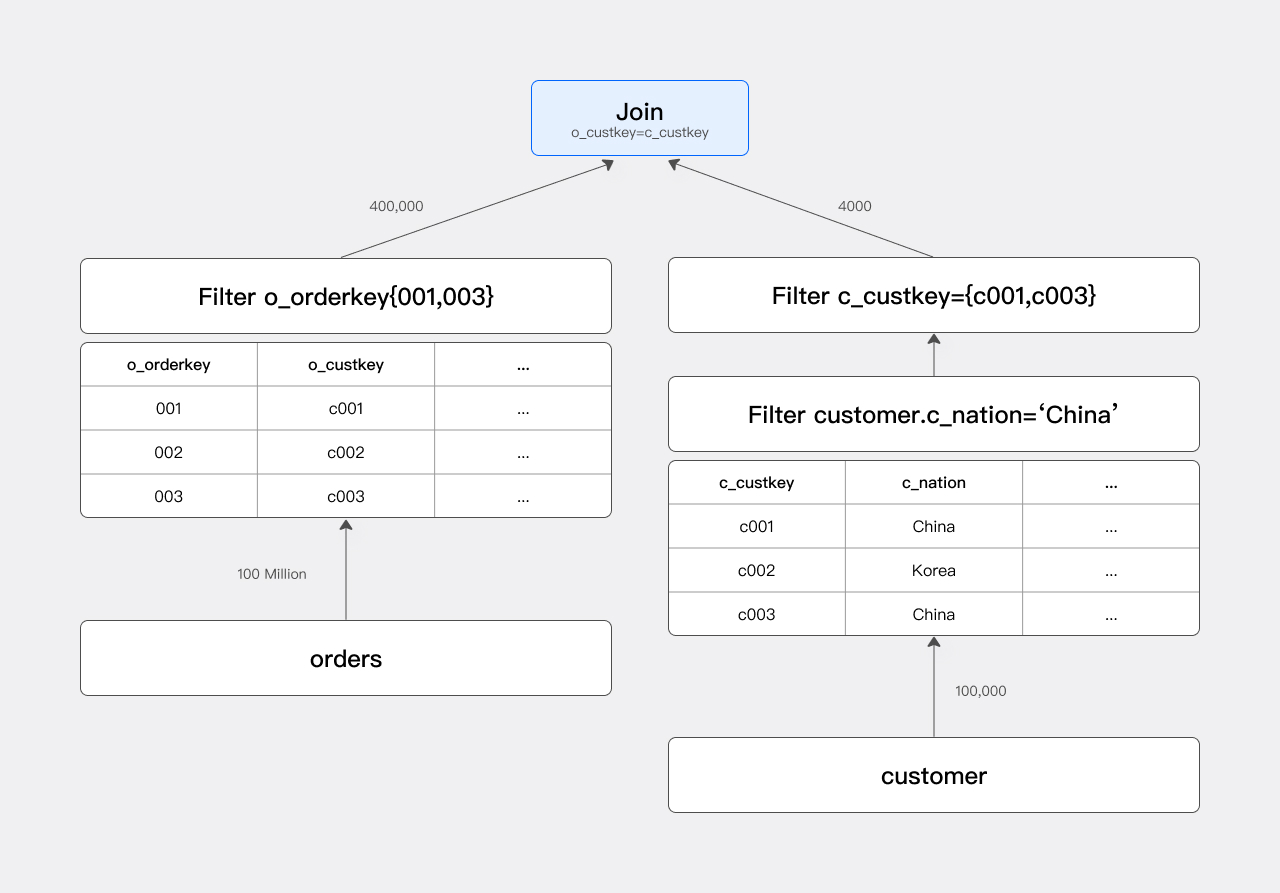
可以看到,通过增加
Orders表上的过滤条件,实际参与Join的Orders行数从1亿下降到40万,查询速度得到大幅提升。 -
实现方法
上述优化效果显著,但优化器并不知道实际被选中的
c_custkey,即集合A。因此,优化器无法在优化阶段静态分析生成一个固定的in-predicate过滤算子。在实际应用中,我们会在
Join节点收集右侧数据后,运行时生成集合A,并将集合A下推给orders表的scan节点。我们通常将这个JRF记为:RF(c_custkey -> [o_custkey])。Doris是一个分布式数据库,为了满足分布式场景的需求,JRF还需要进行一次合并。假设上述例子中的Join是一个Shuffle Join,那么这个Join有多个Instance,每个Join只处理orders和customer表的一个分片。因此,每个Join Instance都只得到了集合A的一部分。在当前
Doris的版本中,我们会选出一个节点作为Runtime Filter Manager。每个Join Instance根据各自分片中的c_custkey生成Partial JRF,并发送给Manager。Manager收集所有Partial JRF后,合并生成Global JRF,再将Global JRF发送给orders表的所有Scan Instance。生成
Global JRF的流程如下图所示: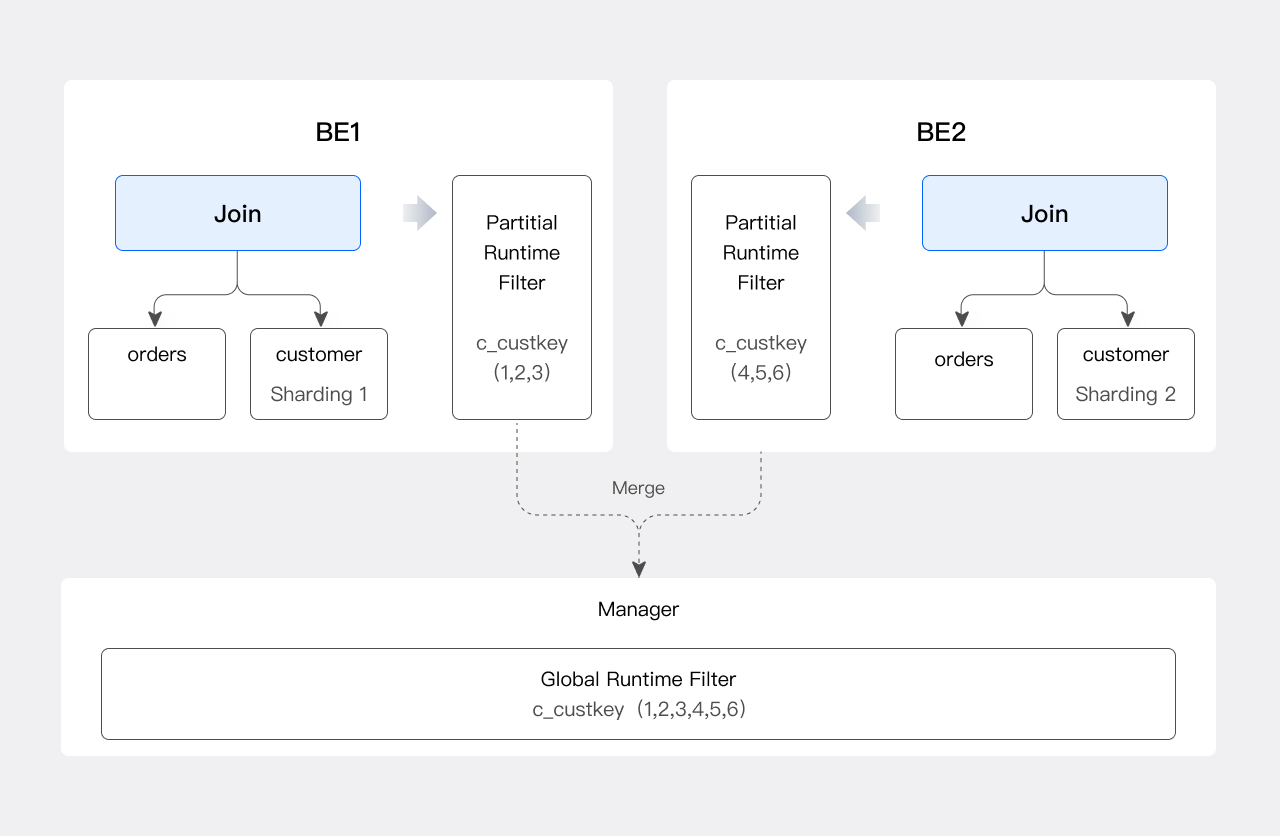
1.2 Filter 类型¶
有多种数据结构均可用于实现 JRF ,但它们在生成、合并、传输、应用等方面效率各异,因此各自适用于不同的场景。
-
In Filter这是实现
JRF的最简单方式。以之前的例子为例,使用In Filter时,执行引擎会在左表上生成谓词o_custkey in (...A 中元素列表...)。通过这个In过滤条件,可以对orders表进行过滤。当集合A中元素数量较少时,In Filter的效率较高。然而,当集合
A中元素数量过大时,使用In Filter会带来性能问题:-
首先,生成
In Filter的成本较高,尤其是在需要进行JRF合并的情况下。因为从不同数据分片对应的Join节点中收集的值可能会有重复,例如,如果c_custkey不是表的主键,那么c001、c003这样的c_custkey可能出现多次,这时就需要进行去重操作,而这个过程比较耗时。 -
其次,当集合
A元素较多时,Join节点与orders表的Scan节点之间传输数据的代价也较高。 -
最后,
orders表的Scan节点执行In谓词也会消耗时间。
基于上述考虑,我们引入了
Bloom Filter。 -
-
Bloom Filter如果对
Bloom Filter不太了解,可以将其理解为一个哈希表。简单来说,Bloom Filter就是一组叠加的哈希表。使用Bloom Filter(或哈希表)进行过滤,利用了以下性质:-
基于集合
A生成哈希表T,如果一个元素不在哈希表T中,那么可以断定这个元素也不在集合A中。反之,则不成立。因此,如果一个
o_orderkey被Bloom Filter过滤掉,那么可以断定在Join的右侧没有相等的c_custkey。但由于哈希碰撞,一些o_custkey即使没有相等的c_custkey,也可能通过Bloom Filter。所以,虽然
Bloom Filter不能实现精准过滤,但仍然能达到一定的过滤效果。 -
哈希表的桶数量决定了过滤的准确率。桶数量越大,
Filter的大小越大,准确性越高,但生成、传输、使用的计算代价也越大。因此,
Bloom Filter的大小也需要在过滤效果和使用代价之间取得平衡。基于此,我们设置了一组可配参数来约束Bloom Filter的最大和最小值,分别是RUNTIME_BLOOM_FILTER_MIN_SIZE和RUNTIME_BLOOM_FILTER_MAX_SIZE。
-
-
Min/Max Filter除了
Bloom Filter外,还有Min-Max Filter可用于进行模糊过滤。如果数据列是有序的,那么Min-Max Filter会有很好的过滤效果。此外,生成、合并、使用Min-Max Filter的代价也远低于In Filter和Bloom Filter。对于非等值的
Join,In Filter和Bloom Filter都无法工作,但Min-Max Filter仍然可以继续发挥作用。假设我们将上例中的查询修改为:SQL 1 2 3
select count(*) from orders join customer on o_custkey > c_custkey where c_name = "China"那么可以选出过滤后最大的
c_custkey,记为n,并将n传给orders表的scan节点。scan节点则会只输出o_custkey > n的行。
1.3 查看 Join Runtime Filter¶
查看一个 Query 上生成了哪些 JRF ,可以通过 explain / explain shape plan / explain physical plan 命令来查看。
我们以 TPC-H Schema 为例,详细说明通过这三个命令如何查看 JRF 。
| SQL | |
|---|---|
1 | |
-
Explain在传统
Explain文本中,JRF(Join Reference File)的信息分布通常出现在Join节点和Scan节点中,具体展示如下图所示:SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
4: VHASH JOIN(258) | join op: INNER JOIN(PARTITIONED)[] | equal join conjunct: (o_custkey[#10] = c_custkey[#0]) | runtime filters: RF000[bloom] <- c_custkey[#0] (150000000/134217728/16777216) | cardinality=1,500,000,000 | vec output tuple id: 3 | output tuple id: 3 | vIntermediate tuple ids: 2 | hash output slot ids: 10 | final projections: o_custkey[#17] | final project output tuple id: 3 | distribute expr lists: o_custkey[#10] | distribute expr lists: c_custkey[#0] | |---1: VEXCHANGE | offset: 0 | distribute expr lists: c_custkey[#0] 3: VEXCHANGE | offset: 0 | distribute expr lists: PLAN FRAGMENT 2 | PARTITION: HASH_PARTITIONED: o_orderkey[#8] | HAS_COLO_PLAN_NODE: false | STREAM DATA SINK | EXCHANGE ID: 03 | HASH_PARTITIONED: o_custkey[#10] 2: VOlapScanNode(242) | TABLE: regression_test_nereids_tpch_shape_sf1000_p0.orders(orders) | PREAGGREGATION: ON | runtime filters: RF000[bloom] -> o_custkey[#10] | partitions=1/1 (orders) | tablets=96/96, tabletList=54990,54992,54994 ... | cardinality=0, avgRowSize=0.0, numNodes=1 | pushAggOp=NONE-
Join端:runtime filters: RF000[bloom] <- c_custkey[#0] (150000000/134217728/16777216)这表示生成了一个
Bloom Filter,编号000,它以c_custkey字段作为输入生成JRF。后面的三个数字和Bloom Filter Size计算相关,我们可以暂时忽略。 -
Scan端:runtime filters: RF000[bloom] -> o_custkey[#10]这表示
000号JRF将作用在orders表的Scan节点上,我们用JRF对o_custkey字段进行过滤。
-
-
Explain Shape Plan在
Explain Plan系列中,我们以Shape Plan为例说明如何查看JRF。SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
mysql> explain shape plan select count(*) from orders join customer on o_custkey=c_custkey where c_nationkey=5; +--------------------------------------------------------------------------------------------------------------------------+ Explain String(Nereids Planner) | +--------------------------------------------------------------------------------------------------------------------------+ PhysicalResultSink | --hashAgg[GLOBAL] | ----PhysicalDistribute[DistributionSpecGather] | ------hashAgg[LOCAL] | --------PhysicalProject | ----------hashJoin[INNER_JOIN shuffle] | ------------hashCondition=((orders.o_custkey=customer.c_custkey)) otherCondition=() buildRFs:RF0 c_custkey->[o_custkey] | --------------PhysicalProject | ----------------Physical0lapScan[orders] apply RFs: RF0 | --------------PhysicalProject | ----------------filter((customer.c_nationkey=5)) | ------------------Physical0lapScan[customer] | +--------------------------------------------------------------------------------------------------------------------------+ 11 rows in set (0.02 sec)如上图所示:
-
Join端:build RFs: RF0 c_custkey -> [o_custkey]表示我们以c_custkey列的数据作为输入,生成一个作用到o_custkey的JRF,编号0。 -
scan端:PhysicalOlapScan[orders] apply RFs:RF0表示orders表被RF0过滤。
-
-
Profile在实际执行中,
BE会将JRF的使用情况输出到Profile(需要set enable_profile=true)。我们仍然以上面的SQL为例,在Profile中查看JRF执行的实际情况。-
Join端SQL 1 2 3 4 5 6 7
HASH_JOIN_SINK_OPERATOR (id=3 , nereids_id=367):(ExecTime: 703.905us) - JoinType: INNER_JOIN 。。。 - BuildRows: 617 。。。 - RuntimeFilterComputeTime: 70.741us - RuntimeFilterInitTime: 10.882us这是
Join的Build侧Profile。在这个例子中,生成JRF耗时70.741us,JRF有617行数据作为输入。JRF的Size和类型由Scan端展示。 -
Scan端SQL 1 2 3 4 5 6 7 8 9 10 11 12
OLAP_SCAN_OPERATOR (id=2. nereids_id=351. table name = orders(orders)):(ExecTime: 13.32ms) - RuntimeFilters: : RuntimeFilter: (id = 0, type = bloomfilter, need_local_merge: false, is_broadcast: true, build_bf_cardinality: false, 。。。 - RuntimeFilterInfo: - filter id = 0 filtered: 714.761K (714761) - filter id = 0 input: 747.862K (747862) 。。。 - WaitForRuntimeFilter: 6.317ms RuntimeFilter: (id = 0, type = bloomfilter): - Info: [IsPushDown = true, RuntimeFilterState = READY, HasRemoteTarget = false, HasLocalTarget = true, Ignored = false] - RealRuntimeFilterType: bloomfilter - BloomFilterSize: 1024在这个部分,我们需要关注以下几点信息:
-
第
5/6行,显示这个JRF的输入和过滤掉的行数。如果Filtered行数越大,那么这个JRF的效果越好。 -
第
10行,IsPushDown = true,表示JRF计算已经下推到存储层。如果下推到存储层,那么有利于存储层实现延迟物化,可以减少IO。 -
第
10行,RuntimeFilterState = READY,表示Scan节点是否应用了JRF。因为JRF采用Try-best机制,如果JRF生成需要很长时间,那么Scan节点在等待一段时间后开始扫描数据,这样输出的数据可能没有经过JRF的过滤。 -
第
12行,BloomFilterSize: 1024,这是一个Bloom Filter,它的size是1024字节。
-
-
1.4 调优¶
关于 Join Runtime Filter 调优,在绝大多数情况下功能为自适应,用户不需要手动调优。
-
开关
JRFSession变量runtime_filter_mode可以控制是否生成JRF。-
打开
JRF:set runtime_filter_mode = GLOBAL -
关闭
JRF:set runtime_filter_mode = OFF
-
-
设定
JRF TypeSession变量runtime_filter_type可以控制JRF的类型,包括:-
IN(1) -
BLOOM(2) -
MIN_MAX(4) -
IN_OR_BLOOM(8)
IN_OR_BLOOM Filter可以让BE根据实际数据行数自适应选择生成IN Filter还是BLOOM Filter。JRF type可以叠加,即根据一个Join条件生成多个类型的JRF。括号中的整数表示Runtime Filter Type的枚举值。如果希望生成多个Type的JRF,那么将runtime_filter_type设置为对应枚举值之和。例如,
set runtime_filter_type = 6,那么将同时为每个Join条件生成BLOOM Filter和MIN_MAX Filter。再比如,在
2.1版本中,runtime_filter_type的默认值是12,即同时生成MIN_MAX Filter和IN_OR_BLOOMFilter。 -
-
设定等待时间
前面提到
JRF使用的是Try-best机制,Scan节点启动前会等待JRF。Doris系统根据运行时状态计算等待时间。但在一些特殊情况下,可能等待时间不够,导致JRF没有生效,那么Scan节点的输出数据行数会比预期多。前面我们已经在Profile部分介绍了如何判断是否等到了JRF。如果Profile中Scan节点RuntimeFilterState = false,那么用户可以手动设置一个更长的等待时间。Session变量runtime_filter_wait_time_ms可以控制Scan节点等待JRF的时间。默认值是1000毫秒。 -
裁剪
JRF在某些情况下,
JRF可能没有过滤性。比如orders表和customer表存在主外键关系,但customer表上没有过滤条件,那么JRF的输入是全体custkey,那么orders表中的所有行都能通过JRF过滤。优化器会根据列统计信息判断JRF的有效性进行裁剪。Session变量enable_runtime_filter_prune = true/false可以控制是否进行裁剪。默认值为true。
2 TopN Runtime Filter¶
2.1 工作原理¶
在 Doris 中,数据是以分块流式的方式进行处理的。因此,当 SQL 语句中包含 topN 算子时, Doris 并不会计算所有结果,而是会生成一个动态的 Filter 来提前对数据进行过滤。
以下面 SQL 语句举例:
| SQL | |
|---|---|
1 | |
此 SQL 语句的执行计划如下图所示:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
在没有 topn filter 的情况下, scan 节点会依次读入 orders 表的每个数据块,并将这些数据块传递给 TopN 节点。 TopN 节点通过堆排序维护着当前已扫描数据 orders 表中排名前 5 行。
由于一个数据 Block 大约包含 1024 行数据,因此在 TopN 处理了第一个数据块后,就能找到该数据块中排名第 5 的行。
假设这个 o_orderdate 是 1995-01-01 ,那么 scan 节点在输出第二个数据块时,就可以使用 1995-01-01 作为过滤条件, o_orderdate 大于 1995-01-01 的行则不需要再发送给 TopN 节点进行计算。
这个阈值会进行动态更新,例如, TopN 在处理第二个经过此阈值过滤的数据块时,如果发现了更小的 o_orderdate ,那么 TopN 会将阈值更新为第一个和第二个数据块中排名第 5 的 o_orderdate 。
2.2 查看 TopN Runtime Filter¶
通过 Explain 命令,我们可以查看优化器规划的 TopN runtime filter 。
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
如上述例子所示:
-
TopN节点上会显示TOPN OPT,表示这个TopN节点会产生一个TopN Runtime Filter。 -
Scan节点上会标注它使用的TopN Runtime Filter是由哪个TopN节点产生的。比如,例子中11行,表示orders表的Scan节点将使用编号为1的TopN节点生成的Runtime Filter,因此在Plan中显示为TOPN OPT: 1。
作为一个分布式数据库, Doris 还需要考虑 TopN 节点和 Scan 节点实际运行的物理机器。因为跨 BE 通信的代价比较高,所以 BE 会自适应地决定是否使用 TopN Runtime Filter ,以及使用的范围。当前,我们实现了 BE 级别的 TopN Runtime Filter ,即 TopN 和 Scan 在同一个 BE 里。这是因为 TopN Runtime Filter 阈值的更新只需要线程间通信,代价比较低。
2.3 调优¶
Session 变量 topn_filter_ratio 可以控制是否生成 TopN Runtime Filter 。
如果 SQL 中 limit 的数量越少,那么 TopN Runtime Filter 的过滤性就越强。因此,系统默认情况下,只有在 limit 数量小于表中数据的一半时,才会启用生成对应的 TopN Runtime Filter 。
例如,如果设置 set topn_filter_ratio=0 ,那么执行以下查询就不会生成 TopN Runtime Filter 。
| SQL | |
|---|---|
1 | |